本項目を読んだ後に「 NtKinect: Kinect V2 を用いた音声認識をDLL化してUnityから利用する 」を読んで、UnityからKinect V2の音声認識を使ってみることをお勧めします。
目次へ[注意] (2019/08/31 追記) コンパイル環境として Visual Studio 2019 や Visual Studio 2017 (後期バージョン)を用いると、 以下のエラーが出てコンパイルできません。
エラー C2440 '既定の引数': 'const wchar_t [1]' から 'BSTR' に変換できません。 KinectV2C:\Program Files\Microsoft SDKs\Speech\v11.0\Include\sapi.h 12519 |
| コンパイルオプションの設定方法 |
|---|
「ソリューションエクスプローラ」 -> プロジェクト名(KinectV2)上で右ドラッグ -> プロパティ -> 構成プロパティ -> C/C++ -> コマンドライン -> 追加のオプション -> /Zc:strictStrings- |
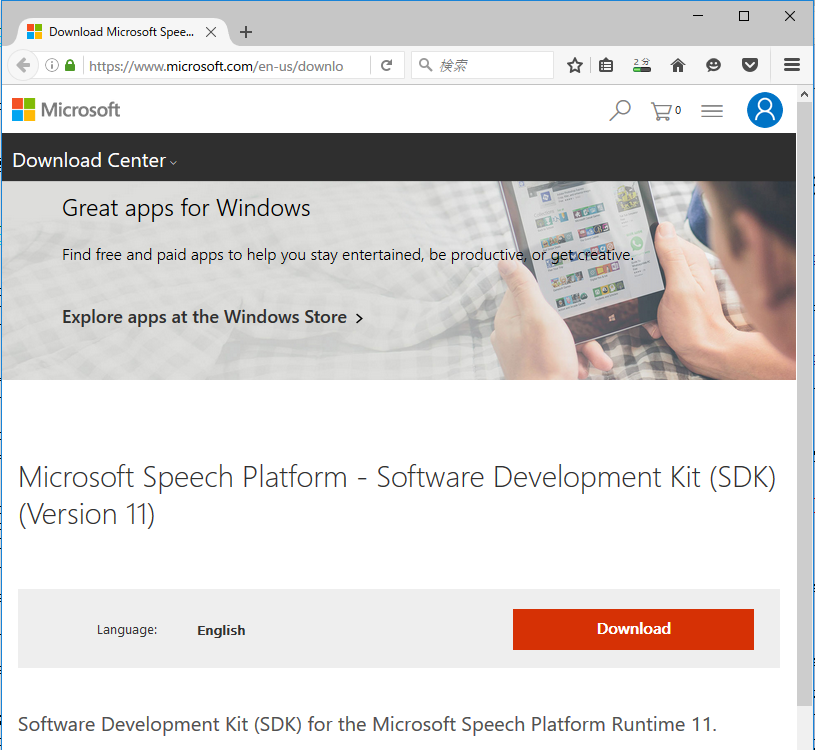
64bit版 x64_MicrosoftSpeechPlatformSDK\MicrosoftSpeechPlatformSDK.msi
選択してダウンロードした msi ファイルをクリックして実行すると、 Speech SDKがC:\Program Files\Microsoft SDKs\Speech\v11.0 以下にインストールされます。
先程インストールした Speech SDK のフォルダから 次の msi ファイルをクリックして実行します。
C:\Program Files\Microsoft SDKs\Speech\v11.0\Redist\SpeechPlatformRuntime.msi
MSKinectLangPack_enUS.msi 英語 MSKinectLangPack_jaJP.msi 日本語
選択してダウンロードした msi ファイルをクリックして、2種類ともインストールして下さい。
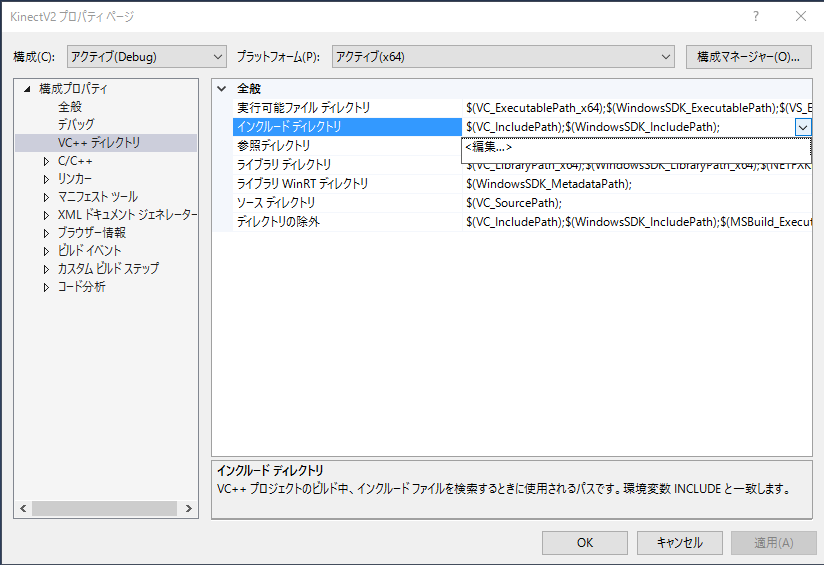
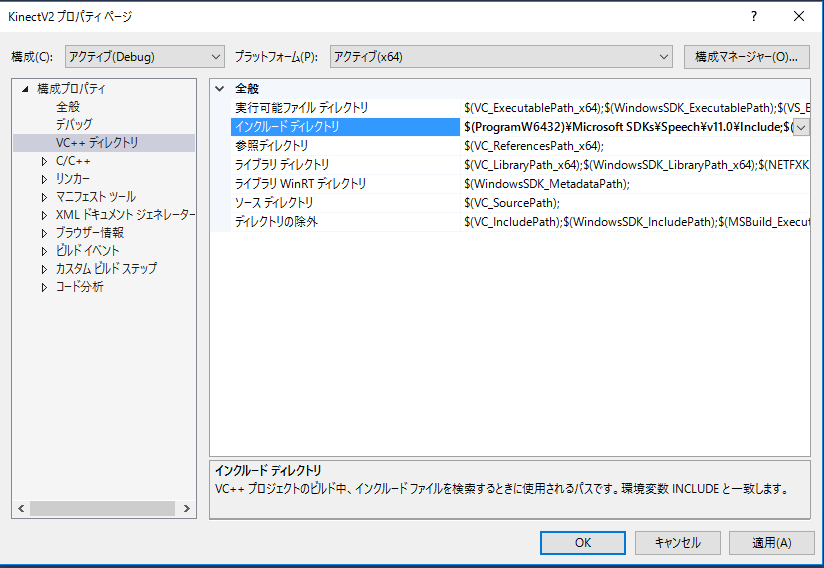
優先順位が高い、他のフォルダに同名のファイルが存在することが多いので注意して下さい。 Visual Studioのプロジェクトの プロパティ -> 構成プロパティ -> VC++ディレクトリで 「インクルードディレクトリ」の一番先頭に
$(ProgramW6432)\Microsoft SDKs\Speech\v11.0\Include;を、「ライブラリディレクトリ」の一番先頭に
$(ProgramW6432)\Microsoft SDKs\Speech\v11.0\Lib;を追加します。 正しいヘッダファイルがincludeされていない、正しいライブラリがリンクされていない などの場合は以下のようにエラーが表示されて実行を中止します。
This sample was compiled against an incompatible version of sapi.h. Please ensure that Microsoft Speech SDK and other sample requirements are installed and then rebuild application. |
failed SpFindBestToken(...略...) |
USE_SPEECH 定数を define してから NtKinect.h を include する と NtKinect の音声認識関係のメソッドや変数が有効になります。
#define USE_SPEECH #include "NtKinect.h" ...
| 返り値の型 | メソッド名 | 説明 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| void | setSpeechLang(string& lang , wstring& grxml ) | 認識する言語をlang に、単語ファイル名を grxml に指定する。 デフォルトではそれぞれ "ja-JP" と L"Grammar_jaJP.grxml" に設定されている。 |
|||||||||||||||
| void | startSpeech() | 音声認識を開始する。 | |||||||||||||||
| void | stopSpeech() | 音声認識を停止する。 | |||||||||||||||
| bool | setSpeech() | 音声認識が開始された状態で呼ばれると、直近の音声データに対して音声認識を試み、以下のメンバ変数の値を設定する。
|
| 型 | 変数名 | 説明 |
|---|---|---|
| bool | recognizedSpeech | 音声認識ができたかを表すフラグ。 speechConfidenceがspeechThreshold以上だとtrueになる。 |
| wstring | speechTag | 音声を認識できた場合に、その単語の「タグ」が設定される。 この「タグ」とは grxml ファイル中の tag タグで指定した値である。 |
| wstring | speechItem | 音声認識ができた場合、その単語の「項目」が設定される。 この「項目」とは grxml ファイル中の item タグで指定した値である。 |
| float | speechConfidence | 音声を認識した結果の信頼度。この値がconfidenceThresholdよりも大きいと音声を認識できたと判断される。 |
| float | confidenceThreshold | 音声認識できたとみなす閾値。代入により値を設定できる。デフォルト値は0.3。 |
64bit版 x64_MicrosoftSpeechPlatformSDK\MicrosoftSpeechPlatformSDK.msi
ダウンロードした msi ファイルをクリックして、インストールします。

SpeechSDK のインストールによってできた、次の msi ファイルをクリックして実行します。
C:\Program Files\Windows\SDKs\Speech\v11.0\Redist\SpeechPlatformRuntime.msi


MSKinectLangPack_enUS.msi 英語 MSKinectLangPack_jaJP.msi 日本語
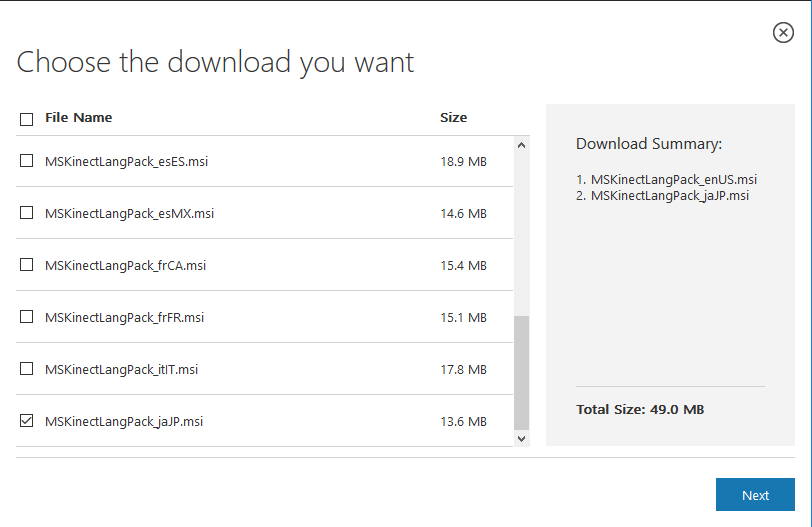
ダウンロードした2つの msi ファイルをクリックして実行します。
必要ないかもしれませんが、念のためです。
WaveFile.hは既にプロジェクトに追加されているはずです。
今回認識させるのは日本語ですが、将来英語を認識させるように変更する場合を考えて、 どちらのファイルもプロジェクトに追加しましょう。
| US英語(usEN)用ファイル | Grammar_enUS.grxml |
| 日本語(jaJP)用ファイル | Grammar_jaJP.grxml |
まず grxml ファイルをプロジェクトのソースフォルダ(この例だと KinectV2_speech/KinectV2/ )に置きます。 それから「ソリューションエクスプローラー」の「リソースファイル」に右クリックで「追加」から「既存の項目」 を選びます。
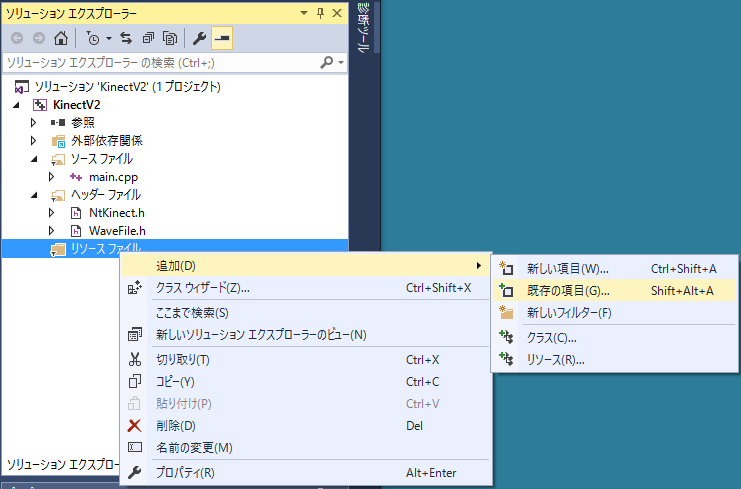
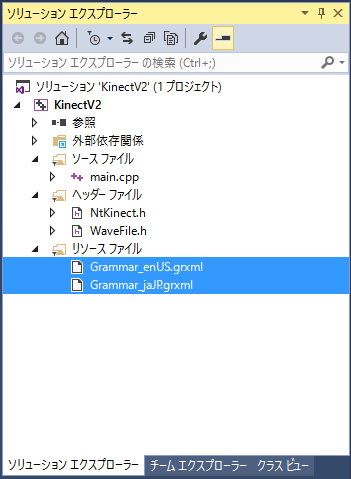
これらのファイルを編集したときは、UTF-8 で保存するようにしましょう。 文法の仕様は https://www.w3.org/TR/speech-grammar/ を参照して下さい。
まず KinectAudioStream.h と KinectAudioStream.cpp をプロジェクトのソースフォルダ (この例だと KinectV2_speech/KinectV2/ )に置きます。 それから「ソリューションエクスプローラー」の「リソースファイル」に右クリックで 「追加」から「既存の項目」を選びます。
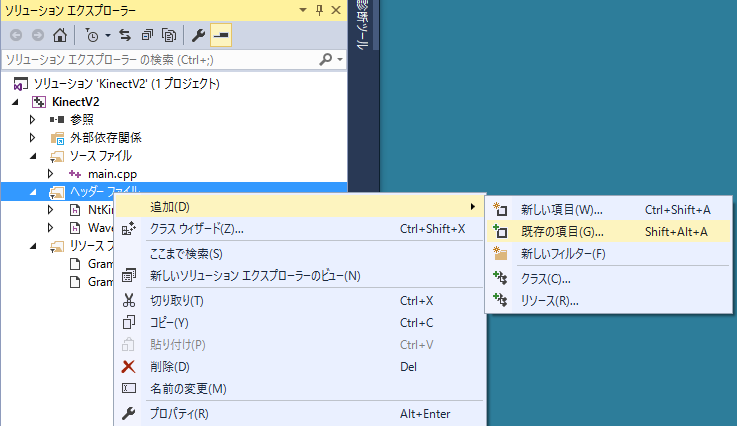
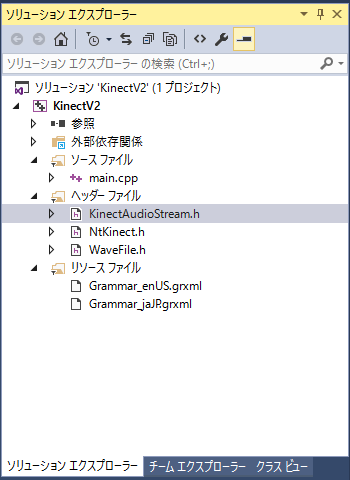
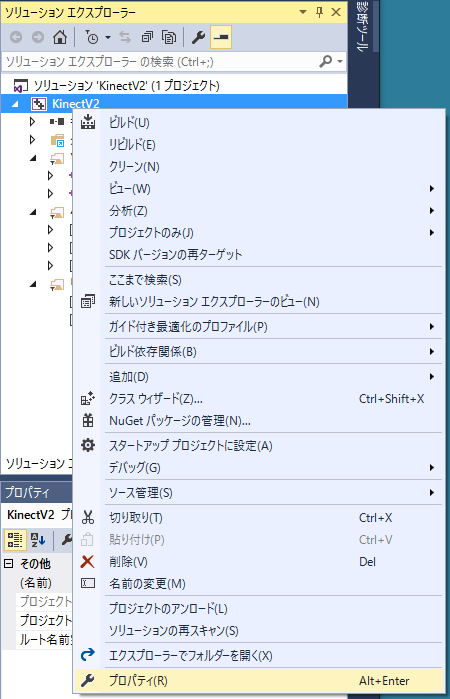
「ソリューションエクスプローラー」から「プロジェクト名(ここでは KinectV2)」の上で右クリックしてメニューから 「プロパティ」を選びます。
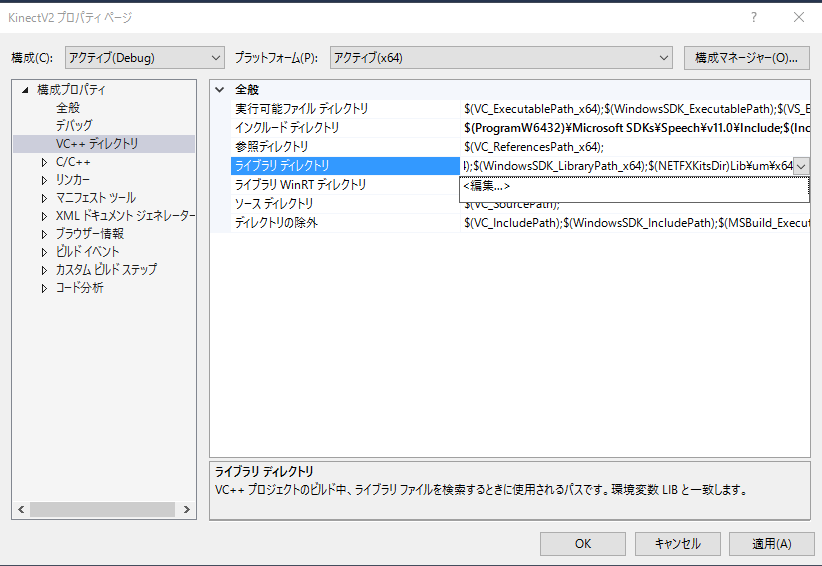
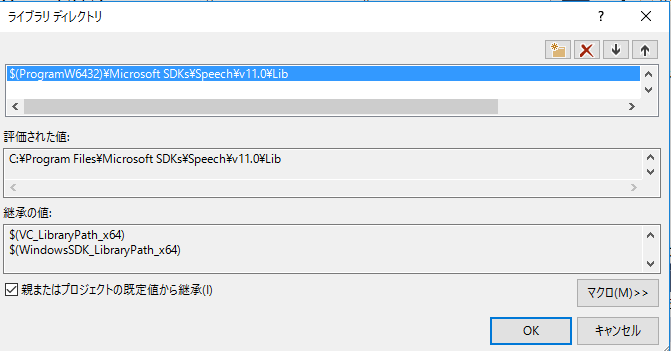
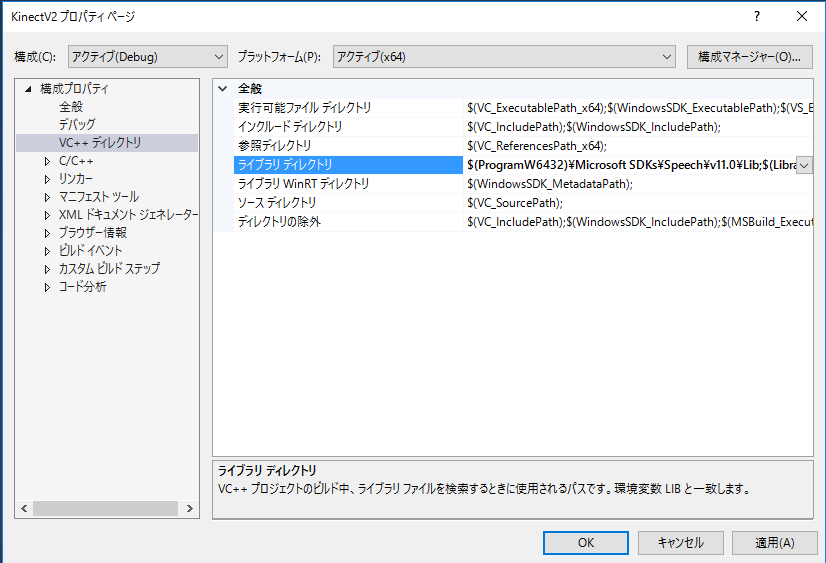
構成プロパティ -> VC++ディレクトリで 「インクルードディレクトリ」の一番先頭に
$(ProgramW6432)\Microsoft SDKs\Speech\v11.0\Include;を、「ライブラリディレクトリ」の一番先頭に
$(ProgramW6432)\Microsoft SDKs\Speech\v11.0\Lib;を追加します。

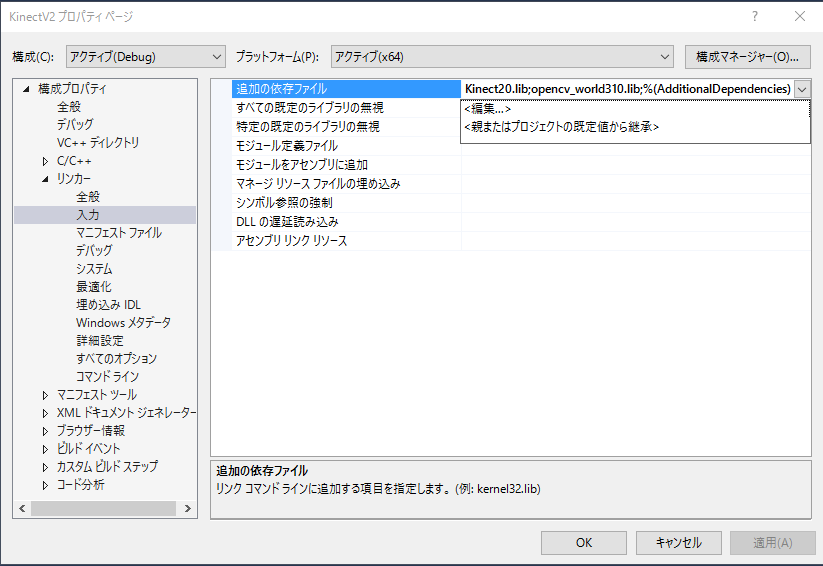
プロジェクトのプロパティの設定で 構成プロパティ -> リンカー -> 入力 -> 追加の依存ファイル -> sapi.libを追加します。
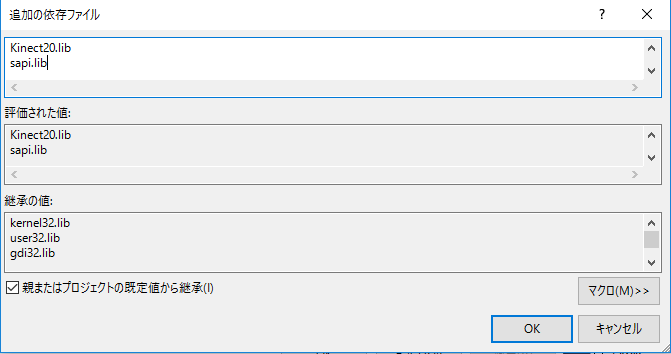
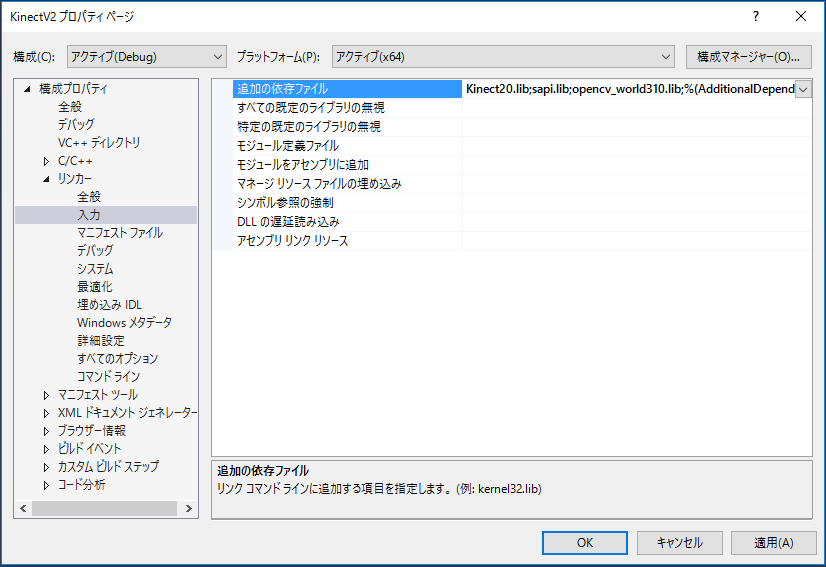
NtKinect.hをincludeする前に USE_SPEECH 定数をdefineします。
音声認識のプログラムはマルチスレッドで動作するので、
プログラムの最初で
Microsoft の Speech SDK によって音声を認識した結果は wchar_t で得られるので、 NtKinect でも結果は wstring で保持しています。 wstring ですので cout にはそのままでは書けませんのでこの例では wcout に出力しています。 wcout はlocale を設定しないとうまく動かないので注意が必要です。
std::wcout.imbue(std::locale("")); // locale 設定
wstringのリテラルは L"EXIT" のようにダブルクォートの前に L がつくことに注意して下さい。
また、cout と wcout を混ぜて使うとよくないので避けて下さい。
kinectに重い処理をさせると音声の取り込みが断続的になり、音声の認識がうまくできなくなります。 そこで、この例ではkinectの他のセンサや、ウィンドウ処理を省略しています。
コンソール画面でのキーボード入力をリアルタイムで判断するために conio.h をincludeして _kbhit(), _getch() 関数を利用しています。
| main.cpp |
#include <iostream> #include <sstream> #include <conio.h> #define USE_SPEECH #include "NtKinect.h" using namespace std; void doJob() { NtKinect kinect; kinect.startSpeech(); std::wcout.imbue(std::locale("")); while (1) { kinect.setSpeech(); if (kinect.recognizedSpeech) { wcout << kinect.speechTag << L" " << kinect.speechItem << endl; } if (kinect.speechTag == L"EXIT") break; if (_kbhit() && _getch() == 'q') break; } kinect.stopSpeech(); } int main(int argc, char** argv) { try { ERROR_CHECK(CoInitializeEx(NULL, COINIT_MULTITHREADED)); doJob(); CoUninitialize(); } catch (exception &ex) { cout << ex.what() << endl; string s; cin >> s; } return 0; } |
音声認識の結果は、コンソールに出力されます。 現在のgrxml では「赤」、「赤色」、「青」、「青色」、「緑」、「緑色」、「終了」、「終わり」が 単語として登録されています。 「終了」または「終わり」を音声認識するとプログラムは終了します。
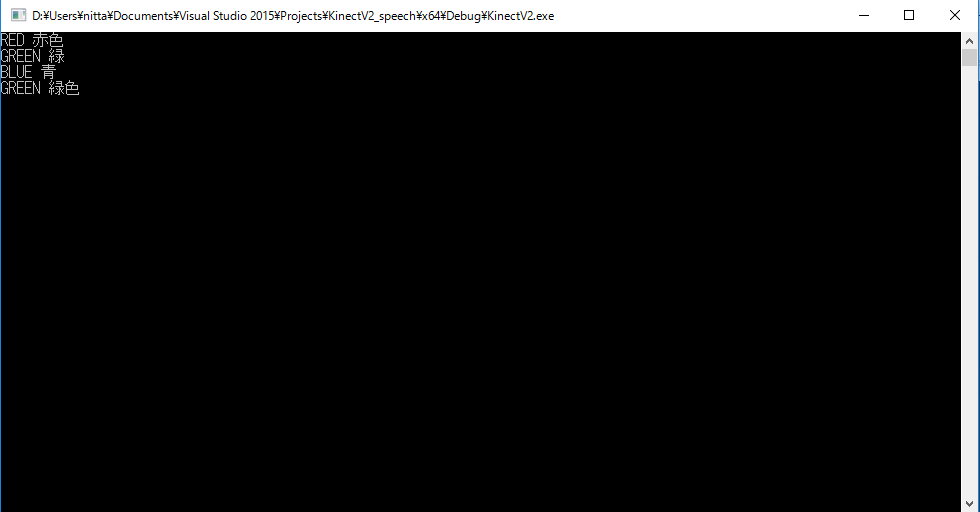
| Grammar_jaJP.grxml |
<?xml version="1.0" encoding="utf-8" ?>
<grammar version="1.0" xml:lang="ja-JP" root="rootRule" tag-format="semantics/1.0-literals" xmlns="http://www.w3.org/2001/06/grammar">
<rule id="rootRule">
<one-of>
<item>
<tag>RED</tag>
<one-of>
<item> 赤 </item>
<item> 赤色 </item>
</one-of>
</item>
<item>
<tag>GREEN</tag>
<one-of>
<item> 緑 </item>
<item> 緑色 </item>
</one-of>
</item>
<item>
<tag>BLUE</tag>
<one-of>
<item> 青 </item>
<item> 青色 </item>
</one-of>
</item>
<item>
<tag>EXIT</tag>
<one-of>
<item> 終わり </item>
<item> 終了 </item>
</one-of>
</item>
</one-of>
</rule>
</grammar>
|
上記のzipファイルには必ずしも最新の NtKinect.h が含まれていない場合があるので、 こちらから最新版をダウンロードして 差し替えてお使い下さい。
現在は閾値が0.3ですが、これを下げて 0.1 などにして誤認識がどう増えるか確認して下さい。
また、認識言語を英語に変更してみましょう。
NtKinect kinect;
kinect.setSpeechLang("en-US", L"Grammar_enUS.grxml"); // <--これを追加すると英語になる
kinect.startSpeech();
| Grammar_enUS.grxml |
<?xml version="1.0" encoding="utf-8" ?>
<grammar version="1.0" xml:lang="en-US" root="rootRule" tag-format="semantics/1.0-literals" xmlns="http://www.w3.org/2001/06/grammar">
<rule id="rootRule">
<one-of>
<item>
<tag>RED</tag>
<one-of>
<item> Red </item>
</one-of>
</item>
<item>
<tag>GREEN</tag>
<one-of>
<item> Green </item>
</one-of>
</item>
<item>
<tag>BLUE</tag>
<one-of>
<item> Blue </item>
</one-of>
</item>
<item>
<tag>EXIT</tag>
<one-of>
<item> Exit </item>
<item> Quit </item>
<item> Stop </item>
</one-of>
</item>
</one-of>
</rule>
</grammar>
|