bodyIndex画像を使うと、どの画素に人間が写っているか判断できます(値が255ではない画素)。 bodyIndex画像は DepthSpace 座標系の座標なので、ColorSpace 座標系の座標に変換してRGB画像と対応させます。 この変換には深度(depth, 距離)を必要とするので、Depth画像も取得します。
Depth画像と同じく 512x424 の解像度でBodyIndex画像を取得することができます。 同時に6人まで区別することができます。
NtKinect では得られたBodyIndex画像はピクセル毎に uchar または cv::Vector3b で表現されます。
| 返り値の型 | メソッド名 | 説明 |
|---|---|---|
| void | setBodyIndex(bool raw = true) | メンバ変数 bodyIndexImage に BodyIndex 画像をセットする。 引数raw がtrue または 引数がない場合、各画素に bodyIndex の値が uchar 型でセットされる。 引数 raw がfalseの場合、bodyIndexを色に変換したデータ cv::Vec3b 型でセットされる。 |
| 型 | 変数名 | 説明 | |||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cv::Mat | bodyIndexImage | BodyIndex画像。 6人まで同時検出が可能で、BodyIndex自体は検出された人ごとに割り当てられた 0〜5の番号である。 BodyIndex画像の各画素の型は uchar の場合と cv::Vec3b の場合がある。 画像の座標は DepthSpace 座標系における位置である。
画素がuchar型のとき各画素の値は、人が検出された場合は 0〜5、検出されない場合は255になる。
uchar pixel = bodyIndexImage.at<uchar>(y , x )
画素がcv::Vec3b 型のときbodyIndex画像は bodyIndex 番号に相当するRGBの値 cv::Vec3b で示される。
cv::Mat pixel = bodyIndexImage.at<cv::Vec3b>(y , x )
|
|||||||||||||||||||||||||||||||||||
512x424の解像度でDepth(距離、深度)画像を取得することができます。 測定可能な距離の範囲は500mm 〜 8000mm ですが、 人間を認識できる範囲は 500mm 〜 4500mm です。
NtKinect では得られたDepth画像はピクセル毎に UINT16 (16bit 符号なし整数) で表現されます。
| 返り値の型 | メソッド名 | 説明 |
|---|---|---|
| void | setDepth(bool raw = true) | メンバ変数 depthImage に Depth 画像をセットする。 引数が「なし」か「true」で呼び出された場合、各画素には距離がmm単位で設定される。 引数が「false」で呼び出された場合、各画素には距離を 65535/4500 倍した値が設定される。 すなわち 0〜4500 (mm) という距離を0 (黒) 〜 65535 (白) という白黒画像の輝度にマップした画像になる。 |
| 型 | 変数名 | 説明 |
|---|---|---|
| cv::Mat | depthImage | Depth 画像。
512x424の大きさで、各ピクセルは UINT16 で表現される。 画像の座標は DepthSpace 座標系における位置となる。
UINT16 depth = rgbImage.at<UINT16>(y , x );
|
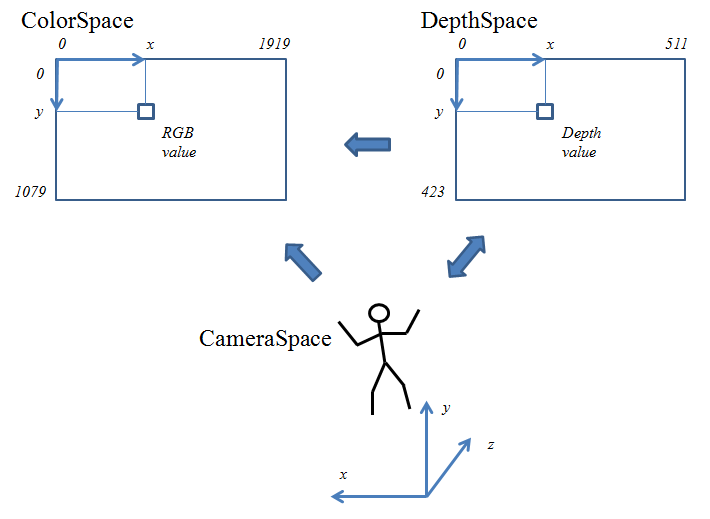
データの種類によって、それを計測するセンサーの位置や解像度が異なります。 そのため、実世界での同じ位置の状態が、センサーによってそれぞれの座標系で表現された値として得られます。 異なるセンサーから得られたデータを同時に利用する場合は、 座標系の変換を行なってどちらかの座標系に合わせる必要があります。
Kinect V2 では、ColorSpace, DepthSpace, CameraSpace という3つの座標系があって、 それぞれの座標を表すデータ型 ColorSpacePoint, DepthSpacePoint, CameraSpacePoint が存在します。
| Kinect for Windows SDK 2.0 の Kinect.h(抜粋) |
|---|
typedef struct _ColorSpacePoint {
float X;
float Y;
} ColorSpacePoint;
typedef struct _DepthSpacePoint {
float X;
float Y;
} DepthSpacePoint;
typedef struct _CameraSpacePoint {
float X;
float Y;
float Z;
} CameraSpacePoint;
|
RGB画像, Depth画像, 関節情報ではそれぞれ使っている座標系が異なります。 RGB画像の座標系は ColorSpace で、Depth画像の座標系は DepthSpace, 関節情報の座標系は CameraSpace です。
| 座標系 | 位置を表す型 | データの種類 |
|---|---|---|
| ColorSpace | ColorSpacePoint | RGB画像 |
| DepthSpace | DepthSpacePoint | depth画像, bodyIndex画像, 赤外線画像 |
| CameraSpace | CameraSpacePoint | skeleton情報 |
| 関節の位置を表すCameraSpace 座標系 |
|---|
|
CameraSpace 座標系は、
(2016/11/12 図を変更し、説明を追記しました)。 |
Kinect V2 の ICoordinateMapper クラス が保持する「座標系の変換用メソッド」は次の通りです。
| 返り値の型 | メソッド名 | 説明 |
|---|---|---|
| HRESULT | MapCameraPointToColorSpace( CameraSpacePoint sp , ColorSpacePoint *cp ) |
CameraSpace 座標系での座標 sp を ColorSpace 座標系での座標に変換してcp にセットする。 返り値はS_OKかエラーコード。 |
| HRESULT | MapCameraPointToDepthSpace( CameraSpacePoint sp , DelpthSpacePoint *dp ) |
CameraSpace 座標系での座標 sp を DepthSpace 座標系での座標に変換してdp にセットする。 返り値はS_OKかエラーコード。 |
| HRESULT | MapDepthPointToColorSpace( DepthSpacePoint dp , UINT16 depth , ColorSpacePoint *cp ) |
DepthSpace 座標系での座標 dp と距離depth から ColorSpace 座標系での座標に変換してcp にセットする。 返り値はS_OKかエラーコード。 |
| HRESULT | MapDepthPointToCameraSpace( DepthSpacePoint dp , UINT16 depth , CameraSpacePoint *sp ) |
DepthSpace 座標系での座標 dp と距離depth から CameraSpace 座標系での座標に変換してsp にセットする。 返り値はS_OKかエラーコード。 |
Kinect V2 で座標系の変換に使う ICoordinateMapper クラス のインスタンスは、 NtKinect のメンバ変数 coordinateMapper に保持されています。
| 型 | 変数名 | 説明 |
|---|---|---|
| CComPtr<ICoordinateMapper> | coordinateMapper | 座標変換を行う ICoordinateMapperのインスタンス。 |
以下の説明では、上記zipファイルを展開した後、フォルダ名を KinectV2_bodyIndex2 と変更したものとします。
プロジェクトに KinectV2というフォルダがあって、そこに main.cpp や NtKinect.h が置かれているはずです。
KinectV2_bodyIndex2\KinectV2\main.cpp
KinectV2_bodyIndex2\KinectV2\NtKinect.h
そのフォルダに cat.jpg をコピーして下さい。
この画像ファイルは フリー素材のサイトから
ダウンロードしたものです。
画像は何でも構いませんが RGB画像と同程度の大きさの方が扱いやすいと思います。
KinectV2_bodyIndex2\KinectV2\cat.jpg

| main.cpp |
#include <iostream> #include <sstream> #include "NtKinect.h" using namespace std; void copyRect(cv::Mat& src, cv::Mat& dst, int sx, int sy, int w, int h, int dx, int dy) { if (sx+w < 0 || sx >= src.cols || sy+h < 0 || sy >= src.rows) return; if (sx < 0) { w += sx; dx -= sx; sx=0; } if (sx+w > src.cols) w = src.cols - sx; if (sy < 0) { h += sy; dy -= sy; sy=0; } if (sy+h > src.rows) h = src.rows - sy; if (dx+w < 0 || dx >= dst.cols || dy+h < 0 || dy >= dst.rows) return; if (dx < 0) { w += dx; sx -= dx; dx = 0; } if (dx+w > dst.cols) w = dst.cols - dx; if (dy < 0) { h += dy; sy -= dy; dy = 0; } if (dy+h > dst.rows) h = dst.rows - dy; cv::Mat roiSrc(src,cv::Rect(sx,sy,w,h)); cv::Mat roiDst(dst,cv::Rect(dx,dy,w,h)); roiSrc.copyTo(roiDst); } void doJob() { NtKinect kinect; cv::Mat cat = cv::imread("cat.jpg"); cv::Mat bgImg; cv::Mat fgImg; while (1) { kinect.setRGB(); cv::cvtColor(kinect.rgbImage,fgImg,CV_BGRA2BGR); // cv::COLOR_BGRA2BGR (in case of opencv3 and later) bgImg = cat.clone(); kinect.setDepth(); kinect.setBodyIndex(); for (int y=0; y<kinect.bodyIndexImage.rows; y++) { for (int x=0; x<kinect.bodyIndexImage.cols; x++) { UINT16 d = kinect.depthImage.at<UINT16>(y,x); uchar bi = kinect.bodyIndexImage.at<uchar>(y,x); if (bi == 255) continue; ColorSpacePoint cp; DepthSpacePoint dp; dp.X = x; dp.Y = y; kinect.coordinateMapper->MapDepthPointToColorSpace(dp, d, &cp); int cx = (int) cp.X, cy = (int) cp.Y; copyRect(fgImg,bgImg,cx-2,cy-2,4,4,cx-2,cy-2); } } cv::imshow("cat", bgImg); auto key = cv::waitKey(1); if (key == 'q') break; } cv::destroyAllWindows(); } int main(int argc, char** argv) { try { doJob(); } catch (exception &ex) { cout << ex.what() << endl; string s; cin >> s; } return 0; } |
まず背景となる画像を変数catに読み込んでおきます。
キーボードから'q'が入力されるまで、以下の処理を繰返し行います。
カメラからRGB画像を取得します。RGB画像のフォーマットは "BGRA" 形式なので、 変数catに読み込んだjpeg画像の形式に合わせて "BGR" 形式に変換して 変数 fgImg に保持します。
合成した画像を保持するのは bgImg 変数なので、背景画像として変数 cat の内容をコピーします。
Depth画像と bodyIndex画像を取得します。 bodyIndex画像の中で人間が写っている画素を見つけたら、 それに対応する ColorSpace 座標系の位置を計算し、 その位置の回りの4x4の領域をRGB画像 fgImg から取り出して合成画像 bgImg に貼り付けます。 bodyIndex画像の座標は DepthSpace 座標系の値なので、 深度情報(Depth画像の値)を利用してColorSpace座標系の値に変換します。 bodyIndex画像(512x424)とRGB画像(1920x1080)では解像度が違うため、 1ピクセルのbodyIndex画像につき 4x4 ピクセルのRGB画像を貼り付けています。
プログラム中で定義している void copyRect(cv::Mat& src , cv::Mat& dst , int sx , int sy , int w , int h , int dx , int dy ) 関数は src 上の (sx , sy ) を左上とする幅 w 高さ h の矩形領域の画像を、 dst 上の (dx , dy ) を左上とする同じ大きさの矩形領域に貼り付けます。 矩形領域がアクセスする画像をはみ出すとエラーが起きるので、はみ出さないように矩形領域の大きさを調整しています。 4x4の画素を貼り付けている
copyRect(fgImg,bgImg,cx-2,cy-2,4,4,cx-2,cy-2); |
for (int y=cy-2; y < cy+2; y++) {
for (int x=cx-2; x < cx+2; x++) {
if (x, y が画像の範囲ならば) {
bgImg.at<cv::Vec3b>(y,x) = fgImg.at<cv::Vec3b>(y,x); // BGR形式のy行x列の画素をコピーする。
}
}
}
|
OpenCVではcv::Mat 型データ(画像)中の 「バイト型データ4個のまとまり(すなわちBGRA形式の画素)」は cv::Vec4b 型として、 「バイト型データ3個のまとまり(すなわちBGR形式の画素)」は cv::Vec3b 型として、 at(int 行 , int 列)メソッドでアクセスできます。
人の画像が抜き出されて、背景画像と合成されています。

上記のzipファイルには必ずしも最新の NtKinect.h が含まれていない場合があるので、 こちらから最新版をダウンロードして 差し替えてお使い下さい。