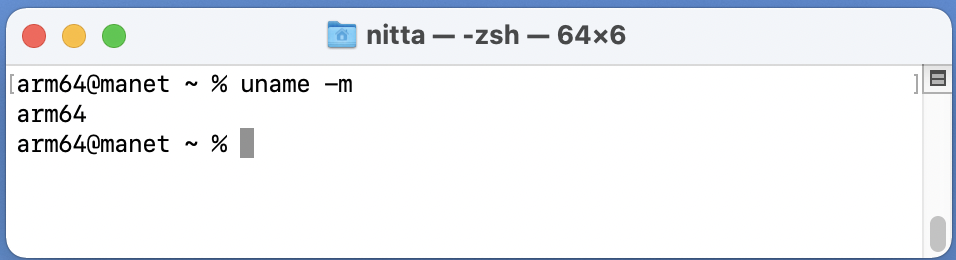
| cond | Meaning | |
|---|
| eq | Equal | 等しい |
| ne | Not equal | 等しくない |
| cs | Carry set (identical to HS) | キャリーが1 |
| hs | Unsigned higher or same (identical to CS) | 符号なしで大か等しい |
| cc | Carry clear (identical to LO) | キャリーが0 |
| lo | Unsigned lower (identical to CC) | 符号無しで小 |
| mi | Minus or negative result | 負 |
| pl | Positive or zero result | 正または0 |
| vs | Overflow | オーバーフロー |
| vc | No overflow | オーバーフロー無し |
| hi | Unsigned higher | 符号ありで大 |
| ls | Unsigned lower or same | 符号ありで小または等しい |
| ge | Signed greater than or equal | 符号付きで以上 |
| lt | Signed less than | 符号付きで未満 |
| gt | Signed greater than | 符号付きで大きい |
| le | Signed less than or equal | 符号付きで以下 |
| al | Always (default) | 無条件 |
Cコンパイラとアセンブラ
値を返す関数のアセンブリ・コード (1)
整数値を返す場合は、x0 を使う。
このレジスタは 64 bit の場合は x0, 32 bit の場合は w0 として指定する。
| sample1.c |
int sample1() {
return 5;
}
|
sample1.s
生成方法: gcc -O -S sample1.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _sample1 ; -- Begin function sample1
.p2align 2
_sample1: ; @sample1
.cfi_startproc
; %bb.0:
mov w0, #5
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
値を返す関数のアセンブリ・コード (2)
実数値を返す場合は v0 を使う。
このレジスタはdouble (64 bit) の場合は d0, float (32 bit) の場合は f0 として指定する。
| sample1b.c |
double sample1() {
return 5.0L;
}
|
sample1b.s
生成方法: gcc -O -S sample1b.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _sample1 ; -- Begin function sample1
.p2align 2
_sample1: ; @sample1
.cfi_startproc
; %bb.0:
fmov d0, #5.00000000
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
引数を渡す関数のアセンブリ・コード
整数やアドレスは x0 - x7 に入れて渡す。
浮動小数点数は v0 - v7 に入れて渡す。
レジスタが足りない場合は、後ろからスタックにpushして渡す。
| sample2の実行例 |
nitta@arm64 % gcc -O sample2a.c sample2b.c sample2c.c -o sample2
nitta@arm64 % ./sample2
450
|
| sample2a.c |
int sum(int x1,int x2, int x3, int x4, int x5, int x6, int x7, int x8, int x9) {
int ret = 0;
ret = x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + x9;
return ret;
}
|
sample2a.s
生成方法: gcc -O -S sample2a.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _sum ; -- Begin function sum
.p2align 2
_sum: ; @sum
.cfi_startproc
; %bb.0:
ldr w8, [sp]
add w9, w1, w0
add w9, w9, w2
add w9, w9, w3
add w9, w9, w4
add w9, w9, w5
add w9, w9, w6
add w9, w9, w7
add w0, w9, w8
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
| sample2b.c |
#include <stdio.h>
extern int sum(int,int,int,int,int,int,int,int,int);
void foo() {
int ret = 0;
ret = sum(10, 20, 30, 40, 50, 60, 70, 80, 90);
printf("%d\n",ret);
}
|
sample2b.s
生成方法: gcc -O -S sample2b.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _foo ; -- Begin function foo
.p2align 2
_foo: ; @foo
.cfi_startproc
; %bb.0:
sub sp, sp, #32 ; =32
stp x29, x30, [sp, #16] ; 16-byte Folded Spill
add x29, sp, #16 ; =16
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
mov w8, #90
str w8, [sp]
mov w0, #10
mov w1, #20
mov w2, #30
mov w3, #40
mov w4, #50
mov w5, #60
mov w6, #70
mov w7, #80
bl _sum
; kill: def $w0 killed $w0 def $x0
str x0, [sp]
Lloh0:
adrp x0, l_.str@PAGE
Lloh1:
add x0, x0, l_.str@PAGEOFF
bl _printf
ldp x29, x30, [sp, #16] ; 16-byte Folded Reload
add sp, sp, #32 ; =32
ret
.loh AdrpAdd Lloh0, Lloh1
.cfi_endproc
; -- End function
.section __TEXT,__cstring,cstring_literals
l_.str: ; @.str
.asciz "%d\n"
.subsections_via_symbols
|
| sample2c.c |
extern void foo();
int main(int argc, char** argv) {
foo();
return 0;
}
|
sample2c.s
生成方法: gcc -O -S sample2c.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _main ; -- Begin function main
.p2align 2
_main: ; @main
.cfi_startproc
; %bb.0:
stp x29, x30, [sp, #-16]! ; 16-byte Folded Spill
mov x29, sp
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
bl _foo
mov w0, #0
ldp x29, x30, [sp], #16 ; 16-byte Folded Reload
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
引数を渡す関数のアセンブリ・コード (2) 実数の場合
| sample21の実行例 |
nitta@arm64 % gcc -O sample21a.c sample21b.c sample21c.c -o sample21
nitta@arm64 % ./sample21
550.0
|
| sample21a.c |
double sum(double x1,double x2, double x3, double x4, double x5, double x6, double x7, double x8, double x9, double x10) {
double ret = 0;
ret = x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + x9 + x10;
return ret;
}
|
sample21a.s
生成方法: gcc -O -S sample21a.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _sum ; -- Begin function sum
.p2align 2
_sum: ; @sum
.cfi_startproc
; %bb.0:
ldp d17, d16, [sp]
fadd d0, d0, d1
fadd d0, d0, d2
fadd d0, d0, d3
fadd d0, d0, d4
fadd d0, d0, d5
fadd d0, d0, d6
fadd d0, d0, d7
fadd d0, d0, d17
fadd d0, d0, d16
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
| sample21b.c |
#include <stdio.h>
extern double sum(double,double,double,double,double,double,double,double,double,double);
void foo() {
double ret = 0;
ret = sum(10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0,100.0);
printf("%lf\n",ret);
}
|
sample21b.s
生成方法: gcc -O -S sample21b.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _foo ; -- Begin function foo
.p2align 2
_foo: ; @foo
.cfi_startproc
; %bb.0:
sub sp, sp, #32 ; =32
stp x29, x30, [sp, #16] ; 16-byte Folded Spill
add x29, sp, #16 ; =16
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
mov x8, #4636737291354636288
mov x9, #140737488355328
movk x9, #16470, lsl #48
stp x9, x8, [sp]
mov x8, #4630826316843712512
fmov d3, x8
mov x8, #4632233691727265792
fmov d4, x8
mov x8, #4633641066610819072
fmov d5, x8
mov x8, #140737488355328
movk x8, #16465, lsl #48
fmov d6, x8
mov x8, #4635329916471083008
fmov d7, x8
fmov d0, #10.00000000
fmov d1, #20.00000000
fmov d2, #30.00000000
bl _sum
str d0, [sp]
Lloh0:
adrp x0, l_.str@PAGE
Lloh1:
add x0, x0, l_.str@PAGEOFF
bl _printf
ldp x29, x30, [sp, #16] ; 16-byte Folded Reload
add sp, sp, #32 ; =32
ret
.loh AdrpAdd Lloh0, Lloh1
.cfi_endproc
; -- End function
.section __TEXT,__cstring,cstring_literals
l_.str: ; @.str
.asciz "%lf\n"
.subsections_via_symbols
|
| sample21c.c |
extern void foo(void);
int main(int argc, char** argv) {
foo();
return 0;
}
|
sample21c.s
生成方法: gcc -O -S sample21c.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _main ; -- Begin function main
.p2align 2
_main: ; @main
.cfi_startproc
; %bb.0:
stp x29, x30, [sp, #-16]! ; 16-byte Folded Spill
mov x29, sp
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
bl _foo
mov w0, #0
ldp x29, x30, [sp], #16 ; 16-byte Folded Reload
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
Cコンパイラのオプティマイズ(最適化)・オプション
| sample3.c |
extern void exit(int);
int main(int argc,char** argv) {
exit(0);
}
|
sample3.s
生成方法: gcc -S sample3.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _main ; -- Begin function main
.p2align 2
_main: ; @main
.cfi_startproc
; %bb.0:
sub sp, sp, #32 ; =32
stp x29, x30, [sp, #16] ; 16-byte Folded Spill
add x29, sp, #16 ; =16
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
mov w8, #0
stur wzr, [x29, #-4]
str w0, [sp, #8]
str x1, [sp]
mov x0, x8
bl _exit
.cfi_endproc
; -- End function
.subsections_via_symbols
|
sample3.s
生成方法: gcc -O -S sample3.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _main ; -- Begin function main
.p2align 2
_main: ; @main
.cfi_startproc
; %bb.0:
stp x29, x30, [sp, #-16]! ; 16-byte Folded Spill
mov x29, sp
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
mov w0, #0
bl _exit
.cfi_endproc
; -- End function
.subsections_via_symbols
|
sample3.c をオプティマイズ・オプションを変えてコンパイルしてみる。
オブジェクト・ファイルを逆アセンブルして出力されたアセンブル言語を調べる。
実行可能ファイルを生成して実行する。 |
vermeer-2:i486 nitta$ gcc -c -g sample3.c
vermeer-2:i486 nitta$ objdump -d -S sample3.o
sample3.o: file format Mach-O 64-bit x86-64
Disassembly of section __TEXT,__text:
_main:
; int main(int argc,char** argv) {
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 48 83 ec 10 subq $16, %rsp
8: b8 05 00 00 00 movl $5, %eax
d: c7 45 fc 00 00 00 00 movl $0, -4(%rbp)
14: 89 7d f8 movl %edi, -8(%rbp)
17: 48 89 75 f0 movq %rsi, -16(%rbp)
; exit(5);
1b: 89 c7 movl %eax, %edi
1d: e8 00 00 00 00 callq 0 <_main+0x22>
vermeer-2:i486 nitta$ gcc -O -c -g sample3.c
vermeer-2:i486 nitta$ objdump -d -S sample3.o
sample3.o: file format Mach-O 64-bit x86-64
Disassembly of section __TEXT,__text:
_main:
; int main(int argc,char** argv) {
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
; exit(5);
4: bf 05 00 00 00 movl $5, %edi
9: e8 00 00 00 00 callq 0 <_main+0xE>
vermeer-2:i486 nitta$ gcc -O sample3.c -o sample3
vermeer-2:i486 nitta$ ./sample3
vermeer-2:i486 nitta$ echo $?
5
vermeer-2:i486 nitta$
|
C言語の関数内にアセンブリ言語のコードを記述する
Arm64については、
arm Developer サイトの
armclang Inline Assembler
の説明が最も詳しいようだ。
__asm キーワードを用いると、C言語の関数中にアセンブリ言語のコードを記述できる。
__asm(code [: output_operand_list [input_operand_list [: clobbered_register_list]]]);
- code ... アセンブリ言語で記述されたコード
- output_operand_list ...オプション。
カンマ ',' 文字で区切ってoutput_operandを記述する。
- input_operand_list ...オプション。
カンマ ',' 文字で区切ってinput_operandを記述する。
- clobbered_register_list ... オプション。
アセンブリ言語のコード中で値が変更されるclobbered_register を記述する。
output_operandとinput_operandはそれぞれ次の要素から構成される。
[ [asm_symbolic_name]] constraint_string (c_variable_name)
- asm_symbolic_name ... オプション。カギ括弧 '[]' で囲まれた、アセンブリ言語中のシンボリック名
- constraint_string ... constraint string (制約文字列)
- 括弧 '()' で囲まれた、Cの式
output_operand と input_operand は
順に0, 1, ... と数字がふられるので、
アセンブリ言語のコード code 中で '$番号' の形(たとえば $0 とか $1)で参照できる。
armのtemplate modifiersについては arm Developer の
Inline assembly template modifiers
を参照のこと。
output_operand のconstraint stringはprefixとして、
'='
(a variable overwriting an existig value)
または
'+' (when reading and writing) から始まる。
prefixの後、1文字以上のconstraintが記述される。
'r' はレジスタを、'm' はメモリを意味する。
GCCのasm文のConstraints で指定する文字の説明はこちらを参照のこと。
CPU固有のConstrainsの説明は
こちらにあり、ARM64は AArch64 として記載されている。
Arm64のConstraintsについては
Arm Compiler armclang Reference Guide の
Constraint codes for AArch64 stateの方がわかりやすいと思う。
constraint string には
Register constraint,
Memory constraint,
Immediate value constraint
の3種類ある。
output_operand のconstraint stringは'=' prefix
(書き込みを意味する)が指定される。たとえば "=r" のように。
| sample4a.c |
int sum(int x1,int x2, int x3, int x4, int x5, int x6, int x7, int x8, int x9) {
int ret;
__asm__(" \n\
mov %w0, %w9 \n\
add %w0, %w0, %w1 \n\
add %w0, %w0, %w2 \n\
add %w0, %w0, %w3 \n\
add %w0, %w0, %w4 \n\
add %w0, %w0, %w5 \n\
add %w0, %w0, %w6 \n\
add %w0, %w0, %w7 \n\
add %w0, %w0, %w8 \n\
"
: "=&r"(ret)
: "r" (x1), "r" (x2), "r" (x3), "r" (x4), "r" (x5), "r" (x6), "r" (x7), "r" (x8), "r" (x9)
:
);
return ret;
}
|
sample4a.s
生成方法: gcc -O -S sample4a.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _sum ; -- Begin function sum
.p2align 2
_sum: ; @sum
.cfi_startproc
; %bb.0:
ldr w9, [sp]
; InlineAsm Start
mov w8, w9
add w8, w8, w0
add w8, w8, w1
add w8, w8, w2
add w8, w8, w3
add w8, w8, w4
add w8, w8, w5
add w8, w8, w6
add w8, w8, w7
; InlineAsm End
mov x0, x8
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
| sample4b.c |
int sum(int x1,int x2, int x3, int x4, int x5, int x6, int x7, int x8, int x9) {
int ret;
__asm__(" \n\
ldr w8, [sp] \n\
add w9, w1, w0 \n\
add w9, w9, w2 \n\
add w9, w9, w3 \n\
add w9, w9, w4 \n\
add w9, w9, w5 \n\
add w9, w9, w6 \n\
add w9, w9, w7 \n\
add %w0, w9, w8 \n\
"
: "=r"(ret)
: /* no input operands */
: "w0", "w1", "w2", "w3", "w4", "w5", "w6", "w7", "w8", "w9"
);
return ret;
}
|
sample4b.s
生成方法: gcc -O -S sample4b.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _sum ; -- Begin function sum
.p2align 2
_sum: ; @sum
.cfi_startproc
; %bb.0:
; InlineAsm Start
ldr w8, [sp]
add w9, w1, w0
add w9, w9, w2
add w9, w9, w3
add w9, w9, w4
add w9, w9, w5
add w9, w9, w6
add w9, w9, w7
add w10, w9, w8
; InlineAsm End
mov x0, x10
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
| sample4c.c |
#include <stdio.h>
extern int sum(int x1,int x2, int x3, int x4, int x5, int x6, int x7, int x8, int x9);
void foo() {
int ret = 0;
ret = sum(10, 20, 30, 40, 50, 60, 70, 80, 90);
printf("%d\n",ret);
}
int main(int argc, char** argv) {
foo();
return 0;
}
|
sample4c.s
生成方法: gcc -O -S sample4c.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _foo ; -- Begin function foo
.p2align 2
_foo: ; @foo
.cfi_startproc
; %bb.0:
sub sp, sp, #32 ; =32
stp x29, x30, [sp, #16] ; 16-byte Folded Spill
add x29, sp, #16 ; =16
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
mov w8, #90
str w8, [sp]
mov w0, #10
mov w1, #20
mov w2, #30
mov w3, #40
mov w4, #50
mov w5, #60
mov w6, #70
mov w7, #80
bl _sum
; kill: def $w0 killed $w0 def $x0
str x0, [sp]
Lloh0:
adrp x0, l_.str@PAGE
Lloh1:
add x0, x0, l_.str@PAGEOFF
bl _printf
ldp x29, x30, [sp, #16] ; 16-byte Folded Reload
add sp, sp, #32 ; =32
ret
.loh AdrpAdd Lloh0, Lloh1
.cfi_endproc
; -- End function
.globl _main ; -- Begin function main
.p2align 2
_main: ; @main
.cfi_startproc
; %bb.0:
stp x29, x30, [sp, #-16]! ; 16-byte Folded Spill
mov x29, sp
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
bl _foo
mov w0, #0
ldp x29, x30, [sp], #16 ; 16-byte Folded Reload
ret
.cfi_endproc
; -- End function
.section __TEXT,__cstring,cstring_literals
l_.str: ; @.str
.asciz "%d\n"
.subsections_via_symbols
|
| sample4a.c + sample4c.c の実行例 |
arm64@manet % gcc -O sample4a.c sample4c.c -o sample4a
arm64@manet % ./sample4a
450
|
| sample4b.c + sample4c.c の実行例 |
arm64@manet % gcc -O sample4b.c sample4c.c -o sample4b
arm64@manet % ./sample4b
450
|
arm Developer: Arm Compiler armclang Reference Guide: Inline Assembly
arm Developer サイトで公開されている Arm Compiler armclang Reference Guide
の中の
armclang Inline Assembler
から関数内inline assemblyに関係する部分だけをまとめる。
__asm [volatile](
"assembly string"
[ : output_operands
[ : input_operands
[ : clobbers ] ] ]
);
assembly string はアセンブリで記述されたコードから構成された1つの文字列である。
文字列の中に'%'で始まるテンプレート
(
"%modifiernumber"
または
"%modifier[name]"
)
を含めることができる。
このtemplate modifier はオプションのコードで、最終的なアセンブリ文の形式を
修飾する。
| 種類 | template
modifier | 説明 |
|---|
| 定数 | c | immediate operand(即値オペランド)。'#'なしで数字を表示する。 |
| n | immediate operand(即値オペランド)。'#'なしで数字を負にして表示する。 |
| メモリ | m | メモリ参照。汎用レジスタにアドレスを保持するように割り当てる。[]つきで表示する。 |
| AArch64 | a | operand constraintは必ず'r'。[]で囲まれたレジスタ名を表示する。メモリオペランドとして適切。 |
| w | operand constraintは必ず'r'。32-bitレジスタ名 W を表示する。 |
| x | operand constraintは必ず'r'。32-bitレジスタ名 X を表示する。 |
| b | operand constraintは'w'か'x'。8-bitレジスタ名 B を表示する。 |
| h | operand constraintは'w'か'x'。16-bitレジスタ名 H を表示する。 |
| s | operand constraintは'w'か'x'。32-bitレジスタ名 S を表示する。 |
| d | operand constraintは'w'か'x'。64-bitレジスタ名 D を表示する。 |
| q | operand constraintは'w'か'x'。128-bitレジスタ名 Q を表示する。 |
| ex01_modifier.c |
int foo() {
int val;
__asm(" \n\
ldr %w0, 1f \n\
b 2f \n\
1: \n\
.word %c1 // %c1 は 0x12345678 と変換される。#0x12345678 だとエラーになる。 \n\
2: \n\
"
: "=r" (val)
: "i" (0x12345678));
return val;
}
|
ex01_modifier.s
生成方法: gcc -O -S ex01_modifier.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _foo ; -- Begin function foo
.p2align 2
_foo: ; @foo
.cfi_startproc
; %bb.0:
; InlineAsm Start
ldr w0, Ltmp0
b Ltmp1
Ltmp0:
.long 305419896
Ltmp1: ; 305419896 は 0x12345678 と変換される。#0x12345678 だとエラーになる。
; InlineAsm End
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
| ex02_modifier.c |
float add(float a, float b) {
float result;
__asm("fadd %s0, %s1, %s2"
: "=w" (result)
: "w" (a), "w" (b));
return result;
}
|
ex02_modifier.s
生成方法: gcc -O -S ex02_modifier.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _add ; -- Begin function add
.p2align 2
_add: ; @add
.cfi_startproc
; %bb.0:
; InlineAsm Start
fadd s0, s0, s1
; InlineAsm End
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
| ex03_modifier.c |
int saturating_add(int a, int b) {
int result;
__asm("add %w0, %w[lhs], %w[rhs]"
: "=r" (result)
: [lhs] "r" (a), [rhs] "r" (b)
);
return result;
}
|
ex03_modifier.s
生成方法: gcc -O -S ex03_modifier.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _saturating_add ; -- Begin function saturating_add
.p2align 2
_saturating_add: ; @saturating_add
.cfi_startproc
; %bb.0:
; InlineAsm Start
add w0, w0, w1
; InlineAsm End
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
number は0から始まり、オペランドリストの順に対応する数字である。
オペランドはオペランドリスト中でnameを与えられていれば、番号ではなく名前で指定できる。
nameは[]で囲むこと。
output_operand_list と input_operand_list
[name] "constraint" (value)
または
"constraint" (value)
constraint は文字列で、assembly string 中でどのように使われるかを指定する。
output_operand中では、そのオペランドがread onlyかread and writeかを指定する。
constraint
modifier | 説明 |
|---|
| = | writeのみ。input_operandのreadが終わった後でしか変更されないことが保証されているので、コンパイラはinput_operandと同じレジスタやメモリに割り当ててもよい。 |
| + | read and write。 |
| =& | writeのみ。input_operandのreadよりも前に変更される可能性があるので、コンパイラはinput_operand同じレジスタに割り当ててはいけない。 |
| 種類 | constraint
code | 説明 |
|---|
| 定数 | i | 「定数」または「大域変数や関数のアドレス」 |
| n | 定数 |
| メモリ | m | メモリ参照。汎用レジスタにアドレスを保持するように割り当てる。[]つきで表示する。 |
| AArch64 | r | 64-bit 汎用レジスタ(X0-X30) |
| w | SIMD or floating-point register (V0-V31) |
| x | operand 必ず 128-bit vector型。(SIMD V0-V15) |
| z | 定数0。XZR or WZR として表示される。 |
| I | 定数[0, 4095]。12 までの左シフトはオプション。 |
| J | 定数[-4095, 0]。12 までの左シフトはオプション。 |
| K | 32 bit論理演算のための定数。 |
| L | 64 bit論理演算のための定数。 |
| M | 32 bitレジスタへのMOV命令のための定数。(MOVZ, MOVN, MOVK) |
| N | 64 bitレジスタへのMOV命令のための定数。(MOVZ, MOVN, MOVK) |
volatileは、assembly stringの中で副作用があるがoutput_operands,
input_operands,
clobbers
でそれが表現されない場合に必要である。
output_operandsがない場合はコンパイラが自動的にvolatile宣言を追加するが、
プログラマがきちんと明記した方がよい。
演習
M1 Mac (MacOS X) 上で演習を行います。
Arm64 のアセンブリ言語で書いたプログラムを実行させてみることにしましょう。
手元の Mac 上で「ターミナル」すなわちシェル(対話環境)を起動して下さい。
多くの部分はCでプログラミングをし、部分的に Arm64 のアセンブリ言語で記述することにしましょう。
課題5a: if文のコードを調べる
if 文のコードを調べなさい。
適切なCの関数を ex5a.c に定義し、gccを使ってアセブリ言語のコード ex5a.s を出力し、
それにわかりやすいコメントを書き加えてから 提出しなさい。
GCCのアセンブリ言語の中では、
- /* と */ に囲まれた領域
- # を書いた後その行の終りまで
がコメントとなります。
あまりに簡単な条件式でコンパイラが成り立つか否かを判断できる場合は、
if 文のコードをださないことがあることに注意して下さい。
つまり、以下のようなCのコードを書いても駄目だ、ということです。
(例)
if (1 > 0) { ... } ←コンパイル時に、いつでも真と判明する
(例2)
int a = 500, b=450;
if (a < b) { ... } ← コンパイル時に、いつでも偽と判明する
課題6a: for文のコードを調べる
for 文のコードを調べなさい。
適切なCの関数を ex6a.c に定義し、gccを使ってアセブリ言語のコード ex6a.s を出力し、
それにわかりやすいコメントを書き加えてから提出して下さい。
課題7a: 値を返す関数をアセンブリ言語で記述する
1から「引数で指定された整数」までの和を返す関数を
機械語で書きなさい。
Cの関数の中に __asm 文でアセンブリ言語の命令を書くこと。
それにわかりやすいコメントを書き加えてから提出しなさい。
GCCではLocal Label の文字列は 'L' で始まる必要がある(たとえばL0001)。
課題8a: 引数を受け取り値を返す関数をアセンブリ言語で記述する
引数として与えられた 64bit整数が奇数であれば1を、
奇数でなければ 0 を返す関数 int isodd(int n) の
本体をアセンブリ言語で書きなさい。
ただし、
__asm の中では機械語命令としては「and だけ」を使うこと。
動作することを確認したら、ソースを提出しなさい。
| ex8a.c |
long isodd(long n) {
long ret = 0;
__asm(" \n\
# and 命令だけを使って題意の動作をするプログラムを書きなさい \n\
"
: "=r"(ret)
: "r" (n)
);
return ret;
}
|
| oddmain.c |
#include <stdio.h>
#include <stdlib.h>
extern long isodd(int);
int main(int argc, char **argv) {
long n;
printf("input integer: ");
scanf("%ld",&n);
printf("%ld\n",isodd(n));
}
|
| oddmain.c + ex8a.c の実行例 |
arm64@manet% gcc -O oddmain.c ex8a.c -o ex8a
arm64@manet% ./ex8a
input integer: 5
1
arm64@manet% ./ex8a
input integer: 4
0
|
[注意] C言語で関数を作っておいてそれをコンパイルしてアセンブリ言語を出させる方法で、
上記の機械語だけを使ったコードがでるかもしれません。
課題9a: 再帰関数をアセンブリ言語で記述する
フィボナッチ数を再帰的に計算する関数 long fib(long) の本体をアセンブリ言語で書きなさい。
fib(0) = 1
fib(1) = 1
fib(n) = fib(n-2) + fib(n-1)
基本的に次と同等の動作をする関数を定義してほしい。
| fib.c |
long fib(long n) {
long result = 1L;
if (n >= 2) {
result = fib(n-1) + fib(n-2);
}
return result;
}
|
fib.s
生成方法: gcc -O -S fib.c |
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _fib ; -- Begin function fib
.p2align 2
_fib: ; @fib
.cfi_startproc
; %bb.0:
stp x20, x19, [sp, #-32]! ; 16-byte Folded Spill
stp x29, x30, [sp, #16] ; 16-byte Folded Spill
add x29, sp, #16 ; =16
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
.cfi_offset w19, -24
.cfi_offset w20, -32
subs x19, x0, #2 ; =2
b.lt LBB0_2
; %bb.1:
sub x0, x0, #1 ; =1
bl _fib
mov x20, x0
mov x0, x19
bl _fib
add x0, x0, x20
b LBB0_3
LBB0_2:
mov w0, #1
LBB0_3:
ldp x29, x30, [sp, #16] ; 16-byte Folded Reload
ldp x20, x19, [sp], #32 ; 16-byte Folded Reload
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
|
ただし、Cコンパイラに余計なことさせないために関数宣言は void fib(void) とすること。
また、__asm の中で使うことのできる機械語命令は、以下の種類だけとする。
stp, str, ldp, ldr, add, sub, cmp, mov, b.lt, b.gt, b.le, b.ge, b, bl, ret
ラベル、レジスタ名、定数などは自由に使用して構わない。
メモリとのデータのやり取りが最小限になるように工夫すること。
すなわち、引数や途中結果などを保存するには、
値が保存されることが保証されているレジスタ(x19 〜 x28 など)
をスタックに保存して用いればよい。
x0 〜 x18 は呼び出した関数で値が変更される可能性がある。)
x31 は stack pointer (sp), x30はlink register (blの時の戻り番地)、x29 は frame pointer として使う。
動作することを確認したら、ソースを提出しなさい。
[注意]
gcc ではleaf function (他の関数を呼び出さない関数)に対する最適化として
Red zone を使用することがある。
すなわち、スタック・ポインタを動かさずに、スタックポインタよりも 128 byte 小さい
アドレスまでのメモリ領域を勝手に使うことがある。
したがって、gccがleaf functionとして認識している関数の中で、__asm の中で
callq (関数呼び出し)を行う場合は、-mno-red-zone オプションを使って
Red zoneによる最適化を禁止する必要がある。
ex9a.cの骨子
void fib(void) として宣言する |
long fib(long n) {
long result;
__asm volatile("\n\
...略... \n\
stp x29, x30, [sp, #-16]! \n\
add x29, sp, #16 \n\
\n\
\n\
// %x0 は変数resultに64bitでアクセスする \n\
// %x1 は変数nに64bitでアクセスする \n\
...略... \n\
\n\
\n\
L01: \n\
// x0 に返り値を入れる \n\
ldp x29, x30, [sp], #16 \n\
...略... \n\
ret \n\
"
: "=&r" (result)
: "r" (n)
: "x0"
);
return result;
}
|
| fibmain.c |
#include <stdio.h>
#include <stdlib.h>
extern long fib(long);
int main(int argc, char **argv) {
long n;
printf("input integer: ");
scanf("%ld",&n);
printf("%ld\n",fib(n));
}
|
| ex9a.c + fibmain.c の実行例 |
arm64@manet % gcc -mno-red-zone -O ex9a.c fibmain.c -o ex9a
arm64@manet % ./ex9a
input integer: 1
1
arm64@manet % ./ex9a
input integer: 2
2
arm64@manet % ./ex9a
input integer: 5
8
arm64@manet % ./ex9a
input integer: 20
10946
|
補足説明
__asm文では次のシンタックスで、C言語の変数をアセンブリ言語の記述の中で利用することができる。
__asm( 機械語命令 : output : input : 値を変更するregister)
便利な機能ではあるが、一部無駄が生じることがあるので注意が必要である。
| fibmain2.c |
#include <stdio.h>
#include <stdlib.h>
extern long fib(long);
int main(int argc, char **argv) {
printf("%ld\n",fib(45L));
}
|
| fib.c + fibmain2.c の実行例 |
arm64@manet % gcc -mno-red-zone -O fib.c fibmain2.c -o fib-time
arm64@manet % time ./fib-time
1836311903
./fib-time 4.94s user 0.02s system 93% cpu 5.286 total
|
| ex9a.c + fibmain2.c の実行例 |
arm64@manet % gcc -mno-red-zone -O ex9a.c fibmain2.c -o ex9b-time
arm64@manet % time ./ex9a-time
1836311903
./ex9a-time 5.40s user 0.02s system 92% cpu 5.848 total
|
上の例では、C言語のみで記述した関数の方が、__asm()文を使ってアセンブリ言語を用いた関数よりも実行速度が速い
状態である。
http://nw.tsuda.ac.jp/