| 目次|前|次 | Javaオブジェクト直列化仕様 Version 6.0 |
第4章 |
ObjectStreamClassは、直列化ストリームに保存されるクラスの情報を提供します。この記述子は、クラスの完全修飾名とその直列化バージョンUIDを提供します。SerialVersionUIDは、このクラスがストリームを書き込んだりストリームから読み込んだりできる、一意のオリジナル・クラス・バージョンを特定します。
package java.io;
public class ObjectStreamClass
{
public static ObjectStreamClass lookup(Class cl);
public static ObjectStreamClass lookupAny(Class cl);
public String getName();
public Class forClass();
public ObjectStreamField[] getFields();
public long getSerialVersionUID();
public String toString();
}
lookupメソッドは、仮想マシン内の指定されたクラスのObjectStreamClass記述子を返します。クラスにserialVersionUIDが定義されていれば、それがクラスから取り出されます。serialVersionUIDがクラスによって定義されていなければ、仮想マシン内のクラスの定義から計算されます。指定されたクラスがSerializableでもExternalizableでもない場合、nullが返されます。
lookupAnyメソッドの動作はlookupメソッドの動作と似ていますが、Serializableを実装しているかどうかに関係なくクラスの記述子を返す点が異なります。Serializableを実装しないクラスのserialVersionUIDは0Lです。
getNameメソッドが返すクラス名の形式は、Class.getNameメソッドが使用する形式と同じになります。
forClassメソッドは、ローカル仮想マシン内のClass (ObjectInputStream.resolveClassメソッドが検出した場合)を返します。それ以外の場合は、nullを返します。
getFieldsメソッドは、このクラスの直列化可能フィールドを表すObjectStreamFieldオブジェクトの配列を返します。
getSerialVersionUIDメソッドは、このクラスのserialVersionUIDを返します。セクション4.6「ストリーム固有識別子」を参照してください。このクラスによって指定されていない場合は、米国国立標準技術研究所によって定義されているSecure Hash Algorithm (SHA)を使って、クラスの名前、インタフェース、メソッド、フィールドから計算されたハッシュ値が返されます。
toStringメソッドは、クラスの名前とserialVersionUIDも含め、クラス記述子の出力可能な表現を返します。
ObjectStreamClass記述子を使って、直列化ストリームに保存されているダイナミック・プロキシ・クラス(java.lang.reflect.ProxyのgetProxyClassメソッドへの呼出しを介して取得されるクラスなど)についての情報を提供することもできます。ダイナミック・プロキシ・クラス自体は直列化可能フィールドを持たず、0LのserialVersionUIDを持ちます。つまり、ダイナミック・プロキシ・クラスのClassオブジェクトがObjectStreamClassのstatic lookupメソッドに渡されると、返されるObjectStreamClassインスタンスは、次のプロパティを持ちます。
ダイナミック・プロキシ・クラスを表現しないObjectStreamClassインスタンスがストリームに書き込まれるときには、クラス名とserialVersionUID、フラグ、およびフィールド数が書き込まれます。クラスによっては、その他の情報が書き込まれることもあります。
SC_SERIALIZABLEおよびSC_EXTERNALIZABLEフラグ・ビットは設定されません。SC_SERIALIZABLEフラグが設定され、フィールド数には直列化可能フィールドの数がカウントされ、そのあとに各直列化可能フィールドの記述子が続きます。記述子は、正規順序で書き込まれます。最初に、プリミティブ型フィールドの記述子がフィールド名でソートされて書き込まれ、次に、オブジェクト型フィールドの記述子がフィールド名でソートされて書き込まれます。名前のソートには、String.compareToが使われます。形式の詳細については、セクション6.4「ストリーム形式の文法」を参照してください。SC_EXTERNALIZABLEフラグを含み、フィールド数は常にゼロです。SC_ENUMフラグを含み、フィールド数は常にゼロです。ダイナミック・プロキシ・クラスおよび非ダイナミック・プロキシ・クラスのObjectStreamClass記述子の直列化表現は、使用する型コードの種類(TC_PROXYCLASSDESCおよびTC_CLASSDESCのどちらか)によって異なります。文法の仕様についての詳細は、セクション6.4「ストリーム形式の文法」を参照してください。
ObjectStreamFieldは、直列化可能クラスの直列化可能フィールドを表現します。クラスの直列化可能フィールドは、ObjectStreamClassから取得できます。
特別なstatic直列化可能フィールドserialPersistentFieldsは、ObjectStreamFieldコンポーネントの配列であり、デフォルトの直列化可能フィールドのオーバーライドに使用されます。
package java.io;
public class ObjectStreamField implements Comparable {
public ObjectStreamField(String fieldName,
Class fieldType);
public ObjectStreamField(String fieldName,
Class fieldType,
boolean unshared);
public String getName();
public Class getType();
public String getTypeString();
public char getTypeCode();
public boolean isPrimitive();
public boolean isUnshared();
public int getOffset();
protected void setOffset(int offset);
public int compareTo(Object obj);
public String toString();
}
ObjectStreamFieldオブジェクトは、クラスの直列化可能フィールドの指定、またはストリームに存在するフィールドの記述に使われます。そのコンストラクタは、表現するフィールドを記述する引数を受け取ります。引数には、フィールドの名前を指定する文字列、フィールドの型を指定するClassオブジェクト、およびデフォルトの直列化/直列化復元が使用中の場合に表現されるフィールドの値を非共有オブジェクトとして読み書きするべきかどうかを示すbooleanフラグ(2つの引数を取るコンストラクタでは暗黙的にfalse)があります(3.1項および2.1項のObjectInputStream.readUnsharedメソッドおよびObjectOutputStream.writeUnsharedメソッドの説明を参照)。
getNameメソッドは、直列化可能フィールドの名前を返します。
getTypeStringメソッドは、フィールドの型シグニチャを返します。
getTypeCodeメソッドは、フィールド型の文字エンコーディングを返します('B'はbyte、'C'はchar、'D'はdouble、'F'はfloat、'I'はint、'J'はlong、'L'は非配列オブジェクト型、'S'はshort、'Z'はboolean、'['は配列)。
isPrimitiveメソッドは、フィールドがプリミティブ型の場合はtrueを返し、それ以外の場合はfalseを返します。
isUnsharedメソッドは、フィールドの値を非共有オブジェクトとして書き込むべき場合はtrueを返し、それ以外の場合はfalseを返します。
getOffsetメソッドは、フィールドを定義するクラスのインスタンス・データ内でのフィールド値のオフセットを返します。
setOffsetメソッドは、getOffsetメソッドから返されたオフセット値をObjectStreamFieldサブクラスで変更できるようにします。
compareToメソッドは、ソートに使用するためにObjectStreamFieldsを比較します。プリミティブ・フィールドは、非プリミティブ・フィールドよりも「小さい」順位にランク付けられます。等しいフィールドは、アルファベット順にランク付けられます。
toStringメソッドは、名前と型による出力可能な表現を返します。
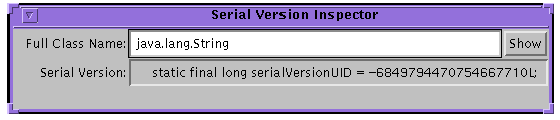
serialVersionUIDを取得できます。-showオプションを指定して呼び出すと、このプログラムは簡単なユーザー・インタフェースを表示します。クラスが直列化可能かどうかを判断し、そのserialVersionUID,を取得するには、クラス名全体を指定し、Enterキーまたは「Show」ボタンを押します。出力された文字列は、コピーして、展開されたクラスにペーストできます。
1つまたは複数のクラス名付きでコマンド行から呼び出されたserialverは、展開中のクラスにコピーするのに適した形式で各クラスのserialVersionUIDを出力します。引数が指定されていないと、このプログラムの使用方法が出力されます。
private static final long serialVersionUID = 3487495895819393L;
ストリーム固有識別子は、クラス名、インタフェース・クラス名、メソッド、およびフィールドの64ビット・ハッシュです。最初のバージョンを除くクラスのすべてのバージョンで、この値を宣言する必要があります。この値は、オリジナル・クラスに宣言することもできますが、必須ではありません。互換性のあるすべてのクラスで、この値は一定です。クラスのSUIDを宣言しない場合は、値はデフォルトでそのクラスのハッシュになります。ダイナミック・プロキシ・クラスおよびenum型のserialVersionUIDは常に、値0Lになります。配列クラスは明示的なserialVersionUIDを宣言できないため、常にデフォルト計算値を持ちますが、配列クラスに関してはserialVersionUID値の一致要件は適用されません。
serialVersionUID値を明示的に宣言することを強くお勧めします。これは、デフォルトのserialVersionUID計算は、コンパイラ実装により異なることがあるクラス詳細によって大きく変わり、そのため直列化復元中に予期しないserialVersionUID競合が発生して直列化復元が失敗する可能性があるためです。
Externalizableクラスの初期バージョンでは、将来的に拡張可能なストリーム・データ形式を出力する必要があります。readExternalメソッドの初期バージョンは、writeExternalメソッドの将来のすべてのバージョンの出力形式を読取り可能でなければいけません。
serialVersionUIDは、クラス定義を反映したバイト・ストリームのシグネチャを使用して計算されます。ストリームのシグネチャの計算には、米国国立標準技術研究所(NIST)のSecure Hash Algorithm (SHA-1)が使用されます。64ビット・ハッシュには、最初の2つの32ビット数が使用されます。プリミティブ・データ型からバイト・シーケンスへの変換には、java.lang.DataOutputStreamが使用されます。ストリームに入力される値は、クラスのJava仮想マシン(VM)仕様によって定義されます。クラス修飾子にはACC_PUBLIC、ACC_FINAL、ACC_INTERFACE、ACC_ABSTRACTフラグを含めることができます。その他のフラグは無視され、serialVersionUIDの計算に影響しません。同様に、フィールド修飾子では、ACC_PUBLIC、ACC_PRIVATE、ACC_PROTECTED、ACC_STATIC、ACC_FINAL、ACC_VOLATILE、ACC_TRANSIENTフラグのみがserialVersionUID値の計算に使用されます。コンストラクタおよびメソッド修飾子では、ACC_PUBLIC、ACC_PRIVATE、ACC_PROTECTED、ACC_STATIC、ACC_FINAL、ACC_SYNCHRONIZED、ACC_NATIVE、ACC_ABSTRACT、ACC_STRICTフラグのみが使用されます。名前と記述子は、java.io.DataOutputStream.writeUTFメソッドが使用する形式で書き込まれます。
private staticおよびprivate transientフィールドを除く):
<clinit>。java.lang.reflect.Modifier.STATIC、32ビット整数として書き込まれる。()V。privateでない各コンストラクタの場合:
<init>。privateでない各メソッドの場合:
DataOutputStreamによって作成されたバイト・ストリームに対して実行され、5つの32ビット値からなるsha[0..4]を作成します。H0 H1 H2 H3 H4は、shaという名前の5つのint値の配列であり、ハッシュ値は次のように計算されます。
long hash = ((sha[0] >>> 24) & 0xFF) |
((sha[0] >>> 16) & 0xFF) << 8 |
((sha[0] >>> 8) & 0xFF) << 16 |
((sha[0] >>> 0) & 0xFF) << 24 |
((sha[1] >>> 24) & 0xFF) << 32 |
((sha[1] >>> 16) & 0xFF) << 40 |
((sha[1] >>> 8) & 0xFF) << 48 |
((sha[1] >>> 0) & 0xFF) << 56;