MUL Xd, Xn, Xm // Xd = Xn * Xm
2 つの 64 bit を乗算した結果の 128 bit のうち、下位 64 bit が Xd に入り、上位 64 bit は捨てられる。
'S'が後ろに付加された命令は存在しないので、条件フラグは設定されない。そのため、overflow (桁溢れ) は検出できない。
符号付き版と符号無し版は別れていない。
全てオペランドはレジスタであり、即値は使えない。
2つの32 bit レジスタ (W) を乗算したときは、結果を保持するレジスタも 32 bit (W) でなくてはならない。
上記の制限を避けるためには、追加された乗算命令を使う。
SMULL や UMULL は 2 つの32 bitレジスタを乗算して結果を 64 bit レジスタに格納する。
SMULLは符号付きで、UMULLは符号無しである。
SMULL Xd, Xn, Xm UMULL Xd, Xn, XmSMULH や UMULH は MUL の計算を補うもので、結果の上位 64 bit を計算する、 SMULHは符号付きで、UMULHは符号無しである。
SMULH Xd, Xn, Xm UMULH Xd, Xn, Xm
MNEG Xd, Xn, Xmm // Xd = - (Xn * Xm) の下位64bit
SMNEGL Xd, Wn, Wm
UMNEGL Xd, Wn, Wm
SDIV Xd, Xn, Xm
UDIV Xd, Xn, Xm
Xd は目的レジスタ、
Xn は分子 (numerator) 、
Xm は分母 (denominator) である。
レジスタは全て X であるか、全てW であるかのどちらかである。
S オプションのついた命令は存在しないので、条件フラグを変更することはない。
0による除算は例外を投げるべきであり、これらの命令で0を返すのは間違いを引き起こしやすい。
これらの命令は quotient (商) のみを返し、余り(remainder) は返さない。
もしも余りが必要ならば remainder = numerator - (quotient * denominator) を計算する。
MADD Xd, Xn, Xm, Xa // Xd = Xa + Xn * Xm
MSUB Xd, Xn, Xm, Xa // Xd = Xa - Xn * Xm
SMADDL Xd, Wn, Wm, Xa
UMADDL Xd, Wn, Wm, Xa
SMSUBL Xd, Wn, Wm, Xa
UMSUBL Xd, Wn, Wm, Xa
for row = 1 to 3
for col = 1 to 3
acum = 0
for i = 1 to 3
acum = acum + A[row, i] * B[i, col]
next i
c[row, col] = acum
next col
next row
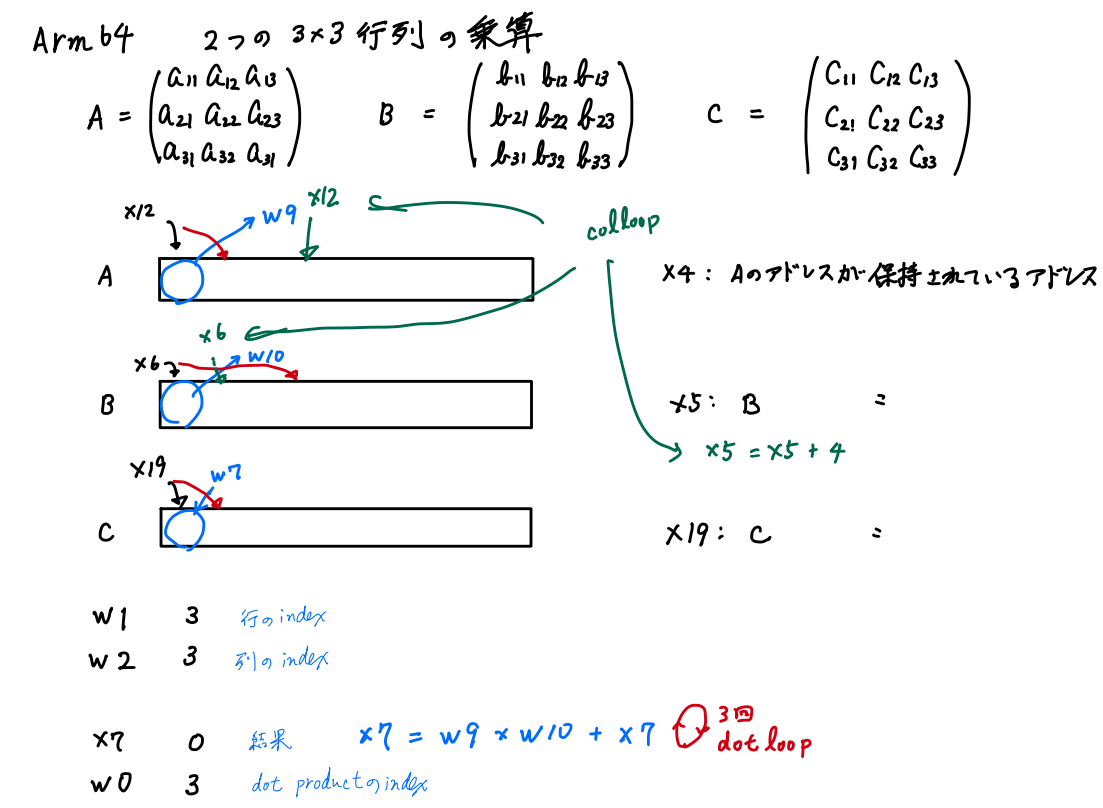
// Multiply 2 3x3 integer matrices
//
// Registers:
// W1 - Row index
// W2 - Column index
// X4 - Address of row
// X5 - Address of column
// X7 - 64 bit accumulated sum
// W9 - Cell of A
// W10 - Cell of B
// X19 - Position in C
// X12 - row in dotloop
// X6 - col in dotloop
.global main
.eqn N, 3 // Matrix dimensions
.eqn WDSIZE, 4 // Size of element
main:
STR LR, [SP, #-16]!
STP X19, X20, [SP, #-16]!
//
MOV W1, #N // row index: 3 --> 0
LDR X4, =A
LDR X19, =C
rowloop:
LDR X5, =B
MOV W2, #N // column index: 3 --> 0
colloop:
MOV X7, #0
MOV W0, #N // dot product counter: 3 --> 0
MOV X12, X4
MOV X6, X5
dotloop:
LDR W9, [X12], #WDSIZE // W9 += [X12]; X12 += 3 //A[row,I]
LDR W10, [X6], #(N*WDSIZE)
SMADDL X7, W9, W10, X7 // X7 = W9 * X10 + X7
SUBS W0, W0, #1
B.NE dotloop
STR W7, [X19], #4 // C[row, col] = dot result; X19 += 4
ADD X5, X5, #WDSIZE
SUBS W2, W2, #1
B.NE colloop
ADD X4, X4, #(N*WDSIZE)
SUBS W1, W1, #1
B.NE rowloop
// 元コードにあった Matrix C を print する部分は省略
//
MOV X0, #0 // return code
LDP X19, X20, [SP], #16
LDR LR, [SP], #16
RET
.data
A: .word 1, 2, 3 // 1st Matrix
.word 4, 5, 6
.word 7, 8, 9
B: .word 9, 8, 7 // 2nd Matrix
.word 6, 5, 4
.word 3, 2, 1
C: .fill 9, 4, 0 // number, size, value
prtstr: .asciz "%3d %3d %3d\n"